scrapy: HTML提前结束,导致css选择器失败
一个网站的反爬
🕐
现场
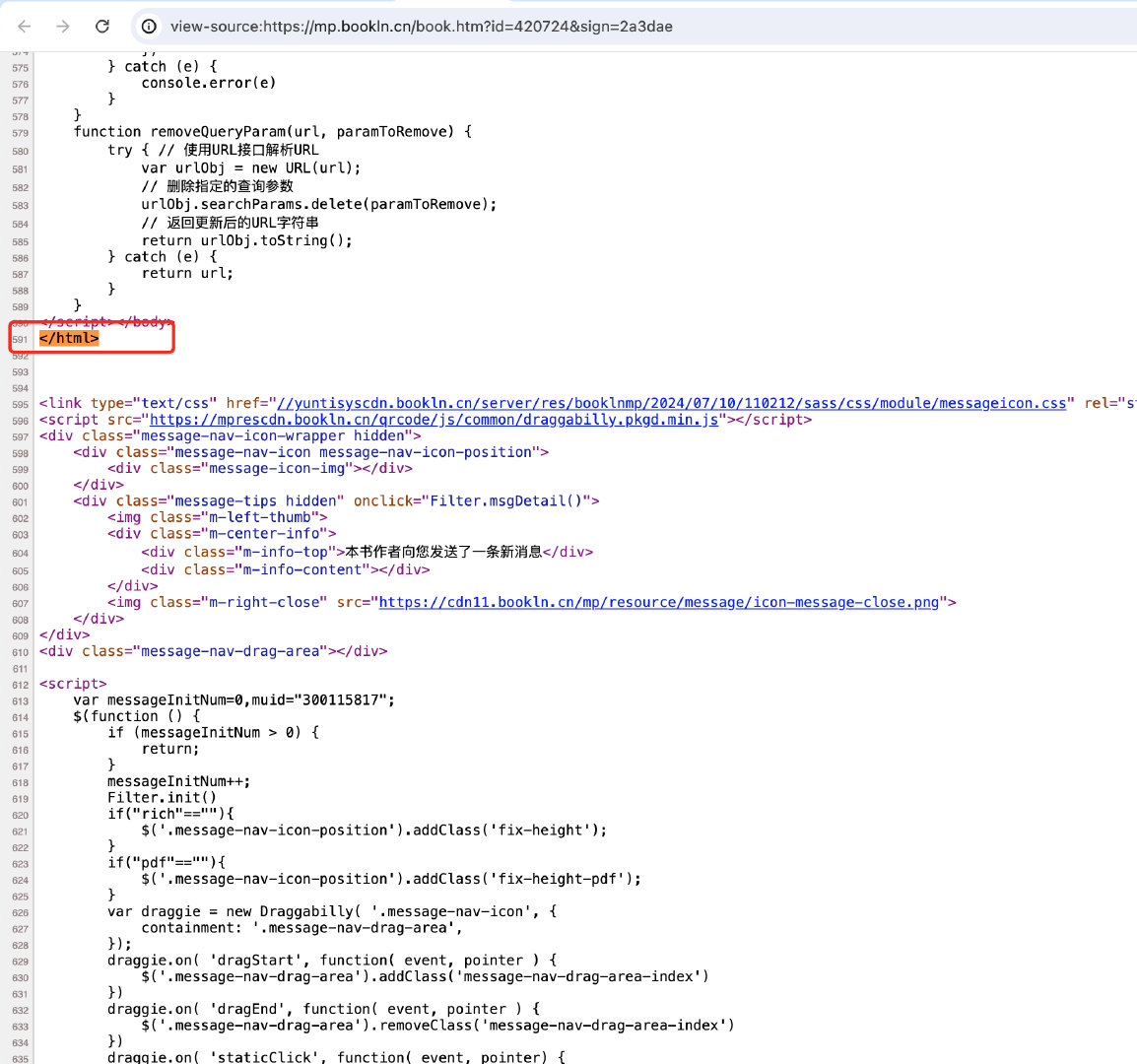
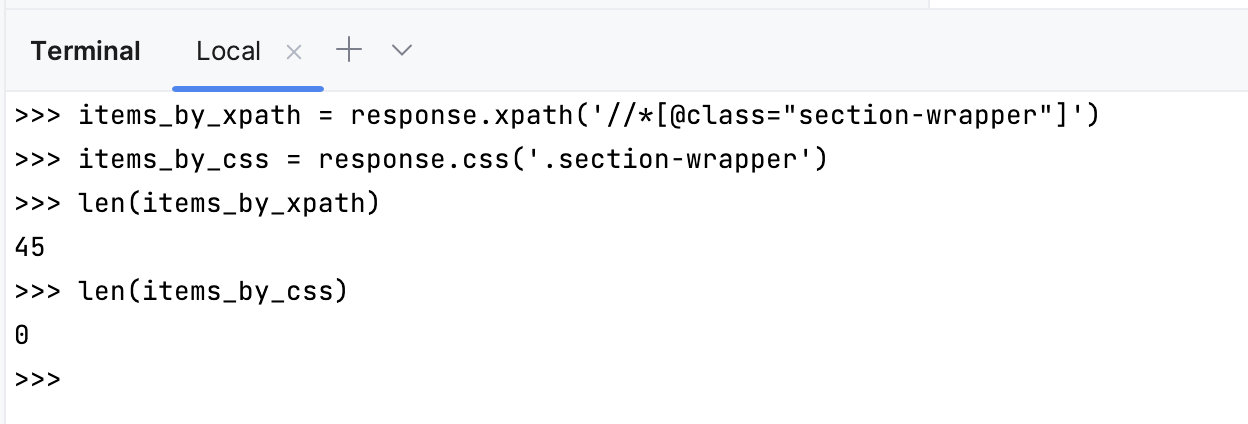
解决方案
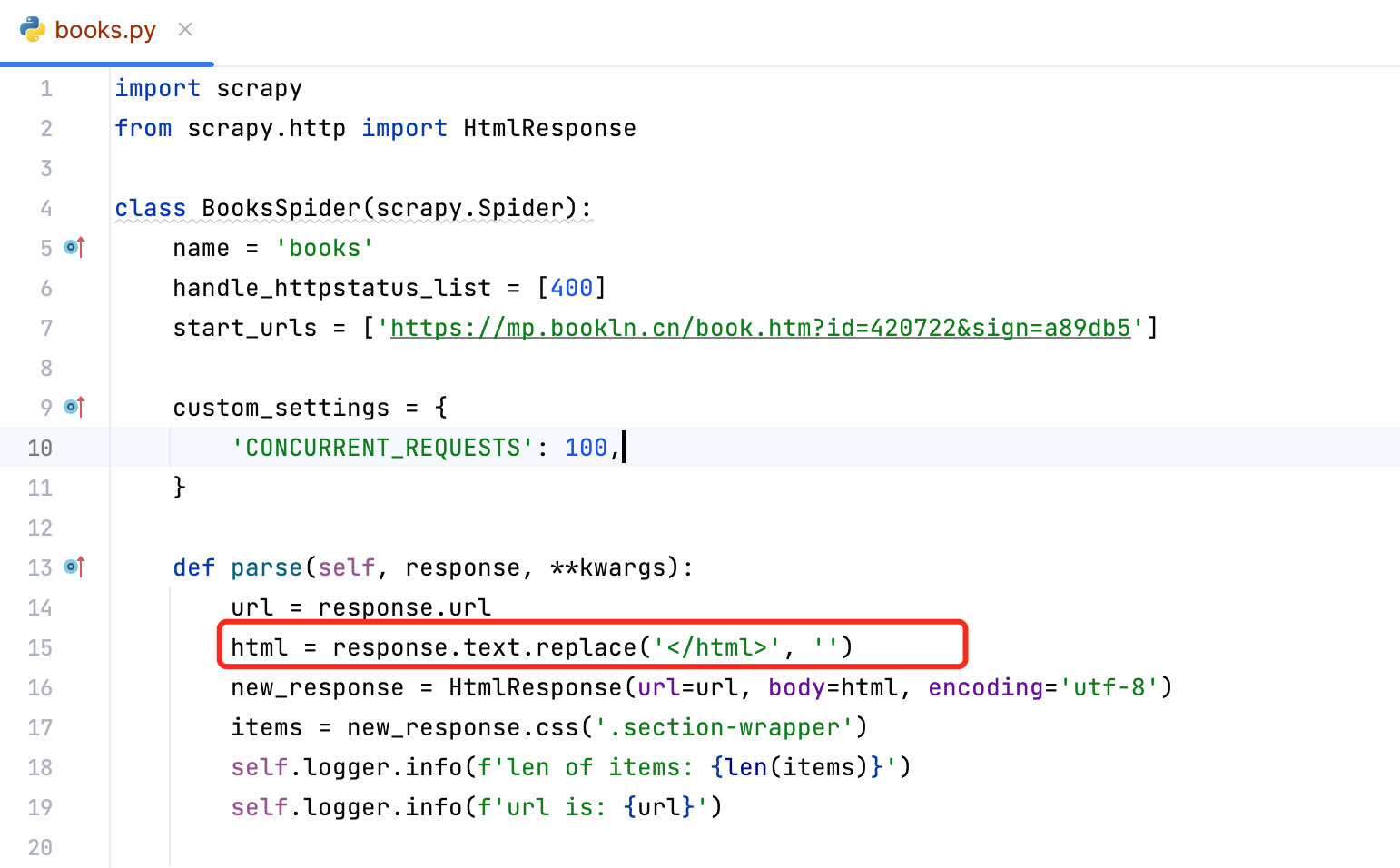
核心代码
import scrapy
from scrapy.http import HtmlResponse
class BooksSpider(scrapy.Spider):
name = 'books'
handle_httpstatus_list = [400]
start_urls = ['https://mp.bookln.cn/book.htm?id=420722&sign=a89db5']
custom_settings = {
'CONCURRENT_REQUESTS': 100,
}
def parse(self, response, **kwargs):
url = response.url
html = response.text.replace('</html>', '')
new_response = HtmlResponse(url=url, body=html, encoding='utf-8')
items = new_response.css('.section-wrapper')
self.logger.info(f'len of items: {len(items)}')
self.logger.info(f'url is: {url}')别人的完整代码