爬虫scrapy框架及案例:阳光政务平台爬虫 list/detail/next_url
P7 05阳光政务平台爬虫
🕐
核心代码
https://wz.sun0769.com/political/index/politicsNewest
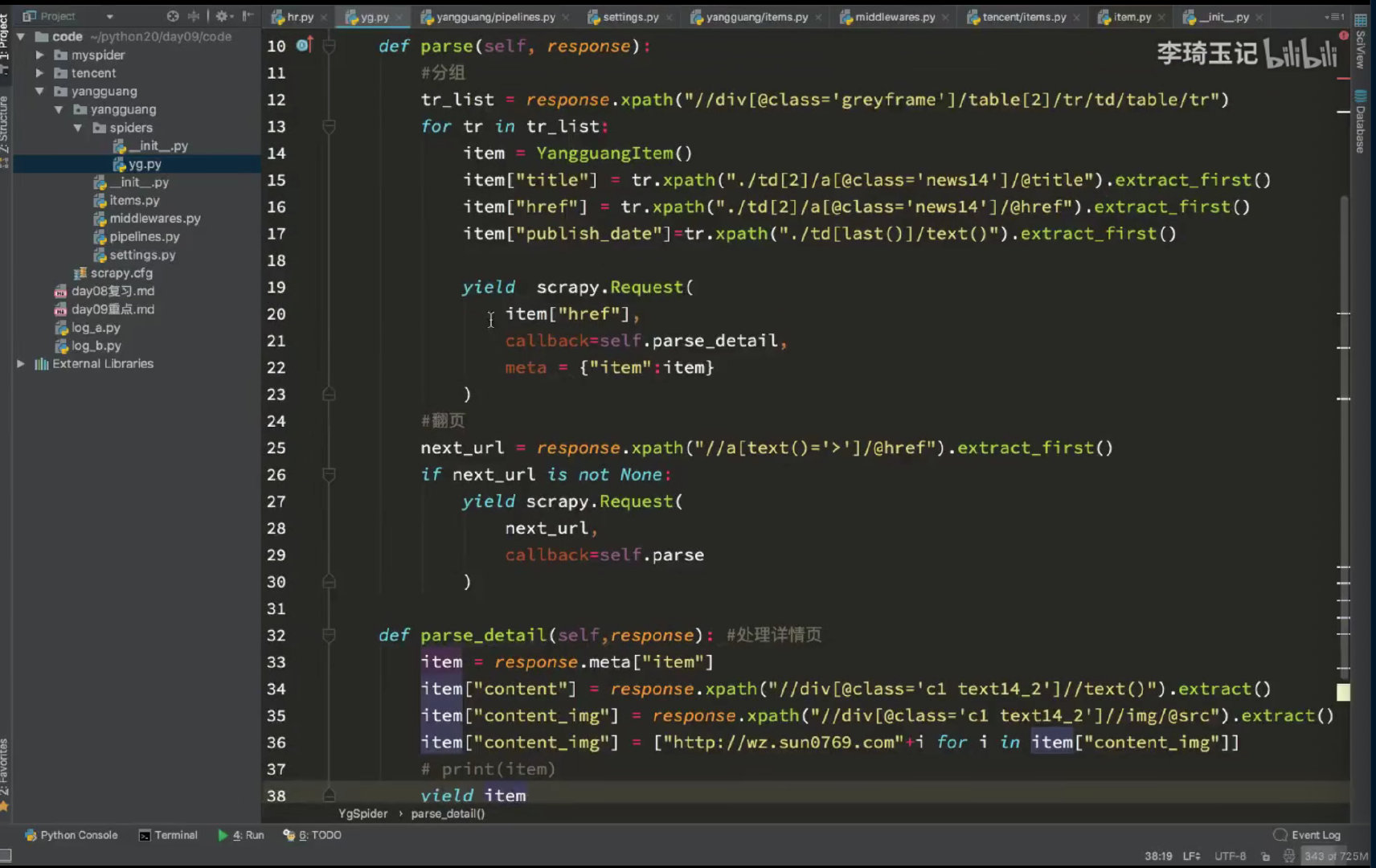
代码解析
- 先把列表分组
list - 列表主要信息采集完之后,扔给
self.parse_detail去采集详情的内容 - 找分页
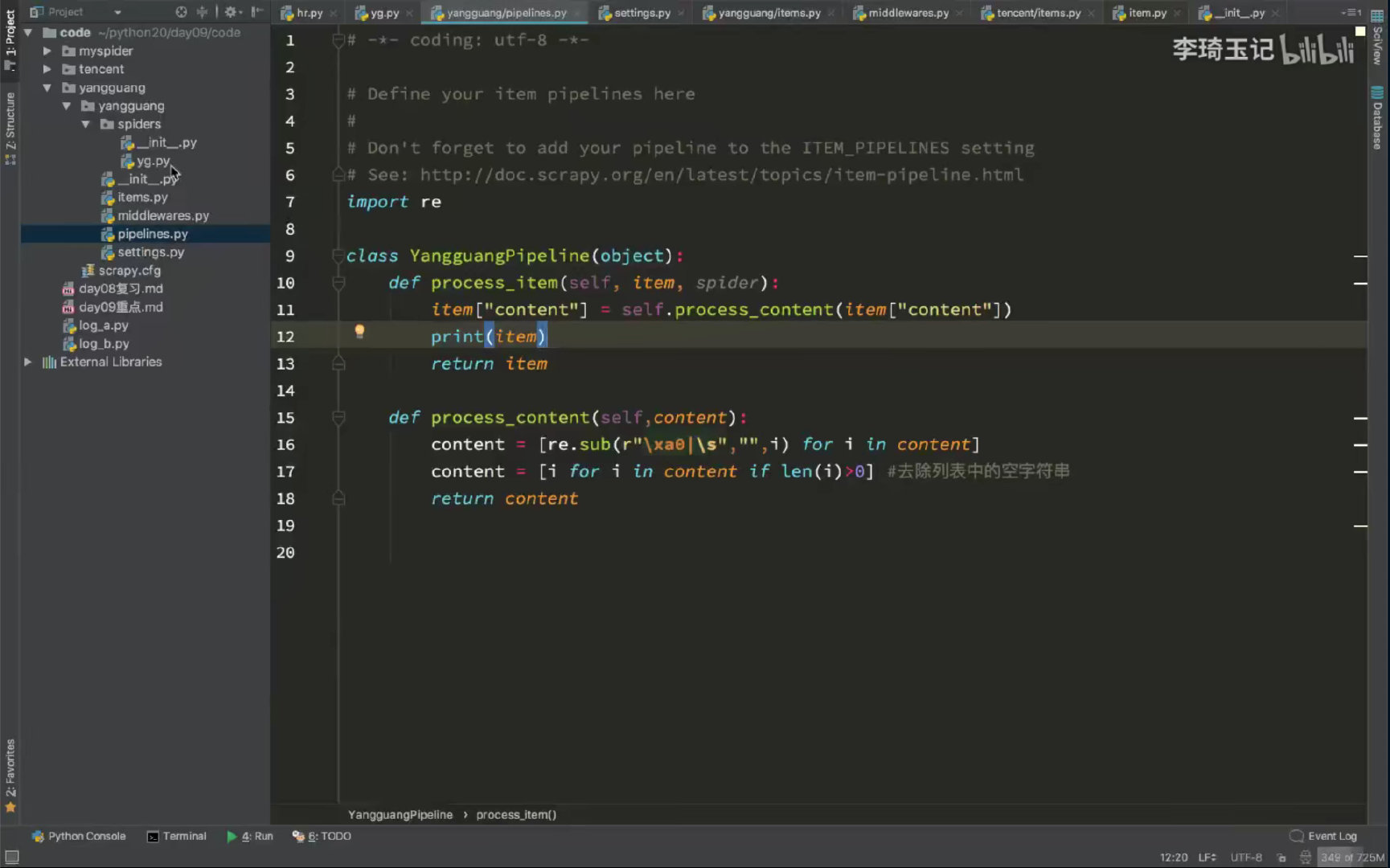
next_url,然后yield再构造 递归逻辑,完成多页采集 - 内容中出现
xa0等特殊的字符 ,需要对内容进行处理;这里用pipline来完成
for--map用法
