python学习:python并发编程 11/12 异步io优化并发爬虫
python并发编程教程
🕐
异步io
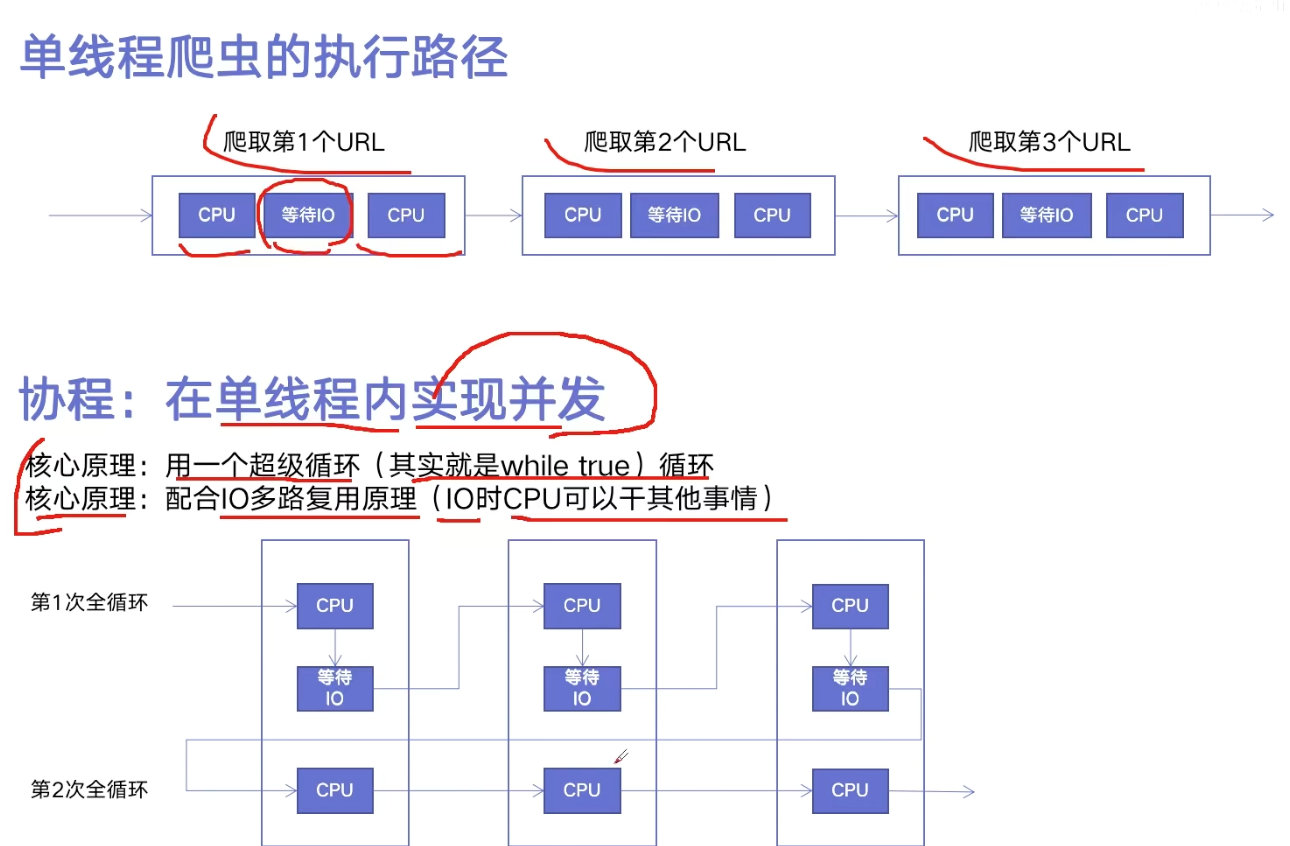

异步io实现的爬虫
import aiohttp
import asyncio
import time
urls = [
f'https://www.cnblogs.com/#p{page}'
for page in range(1, 10 + 1)
]
async def async_crawl(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
res = await response.text()
print(f'Crawl url and len of res: {url}, {len(res)}')
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_crawl(url))
for url in urls
]
# amain with loop
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(f'Async total time: {end - start}')信号量
控制并发度,总量控制在一定的范围内。

加入信号量,控制异步并发的代码如下
import aiohttp
import asyncio
import time
semaphore = asyncio.Semaphore(3)
urls = [
f'https://www.cnblogs.com/#p{page}'
for page in range(1, 10 + 1)
]
async def async_crawl(url):
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
res = await response.text()
print(f'Crawl url and len of res: {url}, {len(res)}')
loop = asyncio.get_event_loop()
tasks = [
loop.create_task(async_crawl(url))
for url in urls
]
# amain with loop
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print(f'Async total time: {end - start}')