爬虫项目小结:gbins-spider,一个物种分类基因库的爬虫
记录一下:一个基本没有做反爬虫的网站数据,竟然有这么多的坑
🕐
项目地址(非公开)
问题记录
- 本地采集,电脑卡
- 本地采集,空间不够(下载文件达到100G)
- 专用服务器采集:python 部署,各种报错处理(后面的:docker 改进)
- 专用服务器采集:经常莫名与本地断连(VPN问题,与代码无关)
- 莫名断掉:可能是服务器网络问题(cron 心跳检测重启服务),效果是进程莫名被杀了,进程守护方案
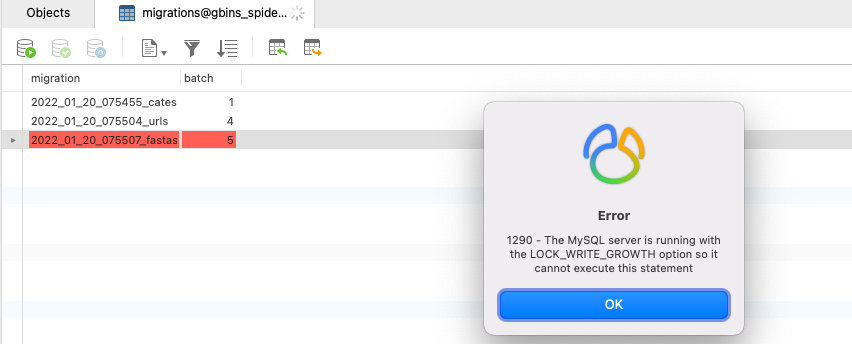
- 利用 MySQL存储遇到的问题:
- 原来
text类型也有装不下fasta基因序列的时间,这里换成longtext解决问题 - 当一张表达到上限的时候:阿里云数据库报错
LOCK_WRITE_GROWTH
- 原来
收获的新技能
- 用 scrapy 代替自己的 ruby/nodejs 爬虫:可以说针对实际项目,完全是秒杀
- 用
多process代替单process方式运行,大大提升采集速度;相当于多进程套多线程的方式进行采集 - 灵活利用
log记录,定位出错,改进spider效率 - 自己写的 jsw-nx 库,在项目中使用,初见成效
- 利用
download-pipline功能完成了近100G文件下载 - 利用
poetry + venv管理项目 - 利用
orator + mysqlclient完成orm方式的入库处理 - 利用
yeoman开发了一个scrapy + orator采集用的专用脚手架程序(afeiship/generator-scrapy) - 利用
@property/@classmethod/@staticmethod重构部分代码 - 巧妙利用
scrapy的爬虫方式处理大量文件
后续可能改进
- 采用
docker部署 - 如果数据量再大,考虑
scrapy-redis分布式方案 - 针对运行时间长的爬虫,考虑加入心跳检测重启服务(应对连
spider_closed整件都没有执行的情况) - 必要的时候的邮件通知功能
- 可以考虑用 pm2 等工具做进程守护
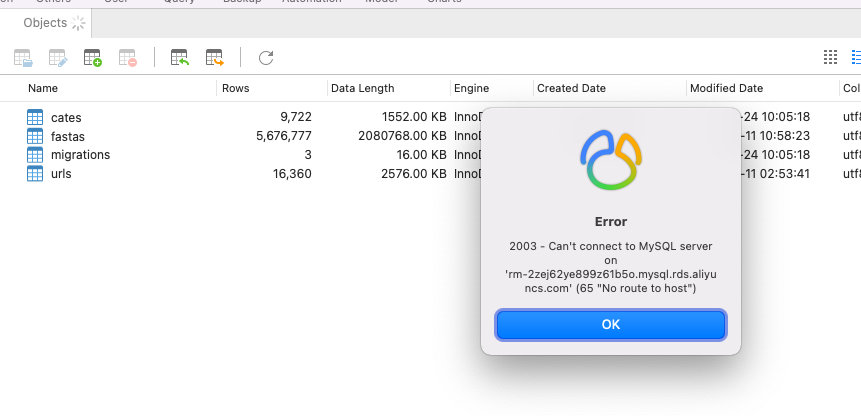
相关出错的截图
LOCK_WRITE_GROWTH先看一下项目用到的数据库结构
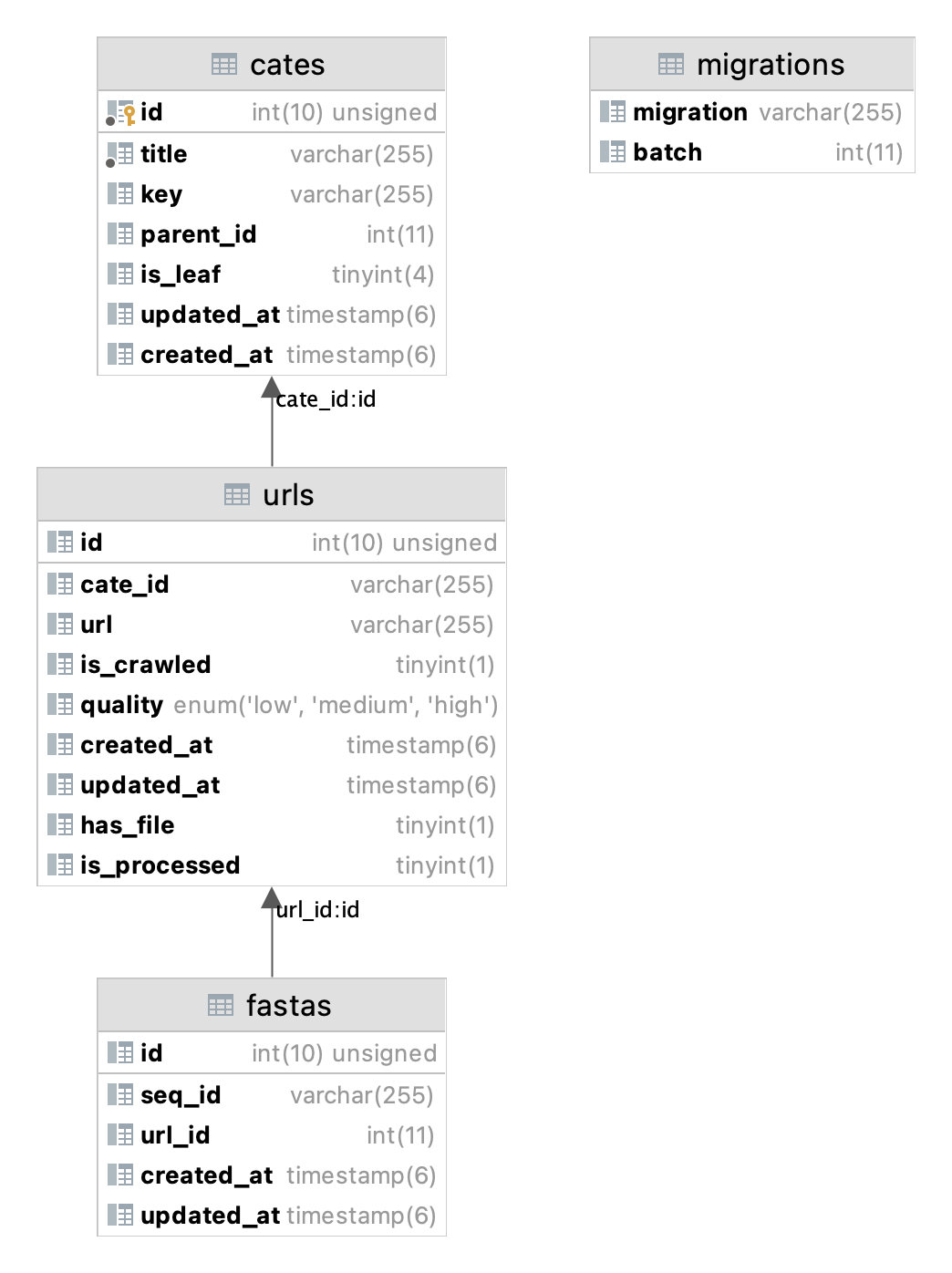
创建数据库
mysql -uroot -p123456 -h127.0.0.1create database gbins_spider CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;项目中常用的 SQL 语句
-- 已经完成处理的文件
SELECT count(*) from urls WHERE has_file = 1 and is_processed = 1;
-- url_id 为1的 seq 数量
SELECT count(seq_id) from fastas WHERE url_id = 1;
-- 做了改变后,清理缓存
flush privileges
-- 将 fastas 任务重新执行一次
UPDATE `gbins_spider`.`urls` SET `is_processed` = 0 WHERE has_file新建一个 scrapy 项目
利用自己的 yeoman scrapy 脚手架新建项目
yo @jswork/scrapy❯ yo @jswork/scrapy
_-----_ ╭──────────────────────────╮
| | │ Welcome to the │
|--(o)--| │ praiseworthy │
`---------´ │ generator-scrapy │
( _´U`_ ) │ generator! │
/___A___\ /╰──────────────────────────╯
| ~ |
__'.___.'__
´ ` |° ´ Y `
? Your project_name scope (eg: `@babel`)? jswork
? Your registry npm
? Your project_name (eg: like this `my-project` )? test-scrapy
? Your description? My test scrapy project..
├── README.md
├── package.json
├── requirements.txt
├── scrapy.cfg
└── test_scrapy
├── __init__.py
├── db.py
├── items.py
├── middlewares.py
├── migrations
│ ├── 2022_01_24_092442_create_entries_table.py
│ └── __init__.py
├── models
│ ├── __init__.py
│ └── entry.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
4 directories, 15 files初始化 venv 环境
venv 放到 .gitignore 文件列表里
python3 -m venv env以多进程方式运行 spider
适用于所有的情况,而且量越大,优势越明显
import scrapy
from scrapy.crawler import CrawlerProcess
class MySpider1(scrapy.Spider):
# Your first spider definition
...
class MySpider2(scrapy.Spider):
# Your second spider definition
...
process = CrawlerProcess()
process.crawl(MySpider1)
process.crawl(MySpider2)
process.start() # the script will block here until all crawling jobs are finished用多 shell 方式完成多 process 运行
适用于量不大,且有明确的 enum 分类参数的情况
nohup scrapy crawl fasta -a quality=low > /dev/null 2>&1 &
nohup scrapy crawl fasta -a quality=medium > /dev/null 2>&1 &
nohup scrapy crawl fasta -a quality=high > /dev/null 2>&1 &日志模块的设置 setting.py
LOG_LEVEL = "INFO"
LOG_FILE = "./logs/gbins_spider.log"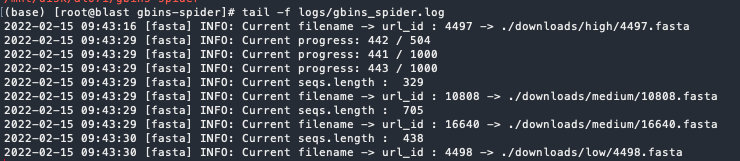
scrapy 下载 spider
- 打开
settings.py的里的DownFastaPipline设置 - 写一个自定义的
pipline
ITEM_PIPELINES = {
'gbins_spider.pipelines.FastaPipline': 200,
'gbins_spider.pipelines.DownFastaPipline': 300,
}class DownFastaPipline(FilesPipeline):
def inc_stats(self, spider, status):
super(DownFastaPipline, self).inc_stats(spider, status)
logger.info('gbins-spider download_status:', status)
def file_path(self, request, response=None, info=None, item=None):
entity = item["entity"]
file_name: str = f"./{entity.quality}/{entity.id}.fasta"
entity.is_crawled = True
entity.save()
return file_name