爬虫scrapy框架及案例:构造请求和腾讯爬虫
P6 03构造请求和腾讯爬虫
🕐
如何实现翻页请求
https://careers.tencent.com/search.html
- 找到下一页地址
- 构造 request 对象,丢给 engine

核心源码实现
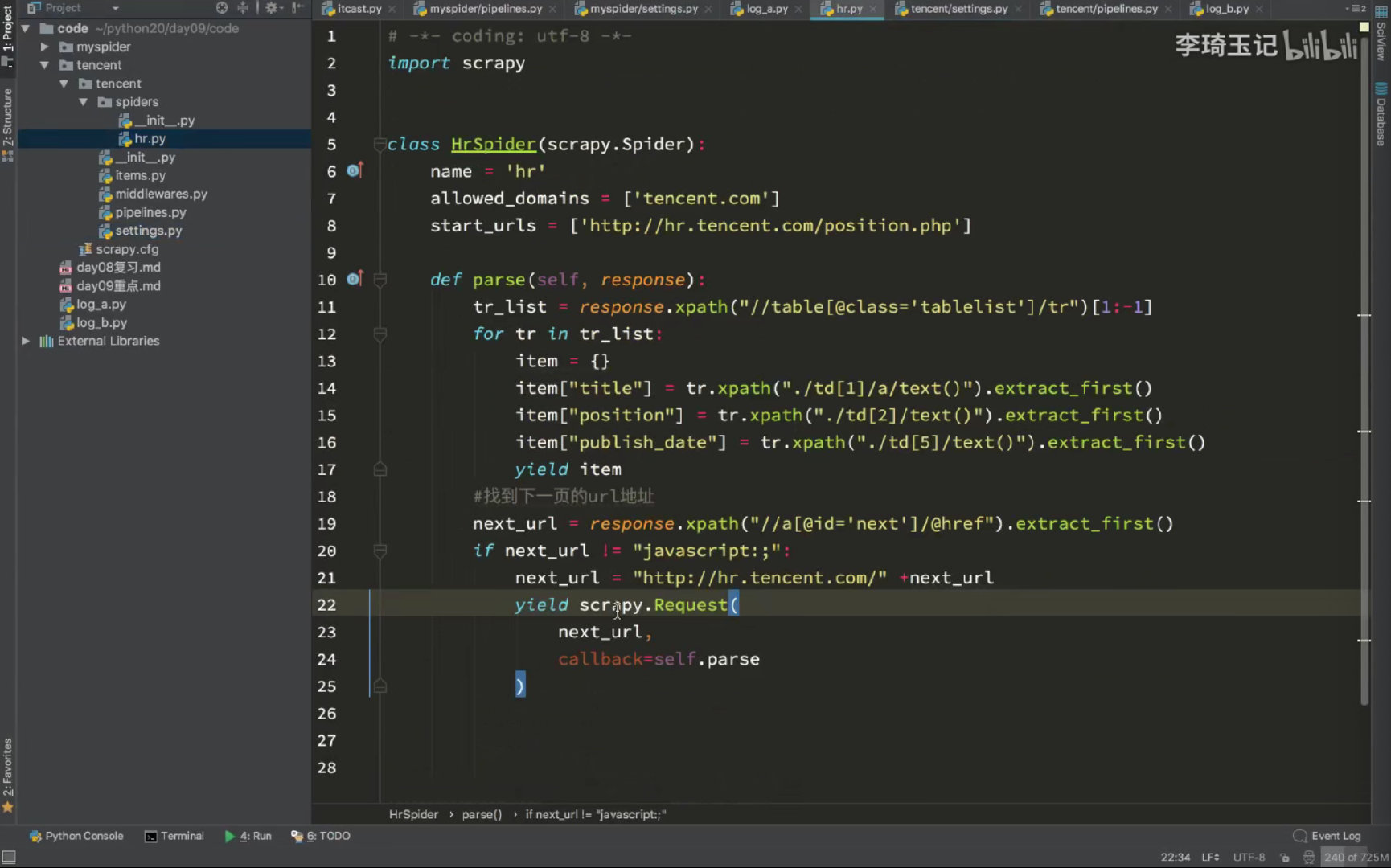
源码解析
- 关键是构造 next_url
- parse方法可以返回 baseItem/dict/还有 scrapy.Request,这个可以从 parse方法的返回定义里查看
- 以 yield 方式返回,可以让 engine 接管后面的事情

在 scrapy.Request 里传参数(meta)
scrapy.Request(next_url, callback=self.parse, meta={item: item})