python学习:python并发编程 01-06
一套讲得不错的并发编程课程
🕐
课程目录
- 01-并发编程简介
- 02-怎样选择:多线程/多进程/多协和
- 03-Python速度慢的罪魁祸首,全局解释器锁GIL
- 04-使用多线程,Python爬虫被加速10倍
- 05-Python实现生产者消费者爬虫
- 06-Python线程安全问题以及解决方案
- 07-Python好用的线程池ThreadPoolExecutor
- 08-Python使用线程池在Web服务中实现加速
- 09-使用多进程multiprocessing模块加速程序的运行
- 10-Python在Flask服务中使用多进程池加速程序运行
- 11-Python异步IO实现并发爬虫
- 12-在异步IO中使用信号量控制爬虫并发度
并发编程简介
为什么要并发编程?
- 提升程序的整体运行速度
- 高级技能,必备的
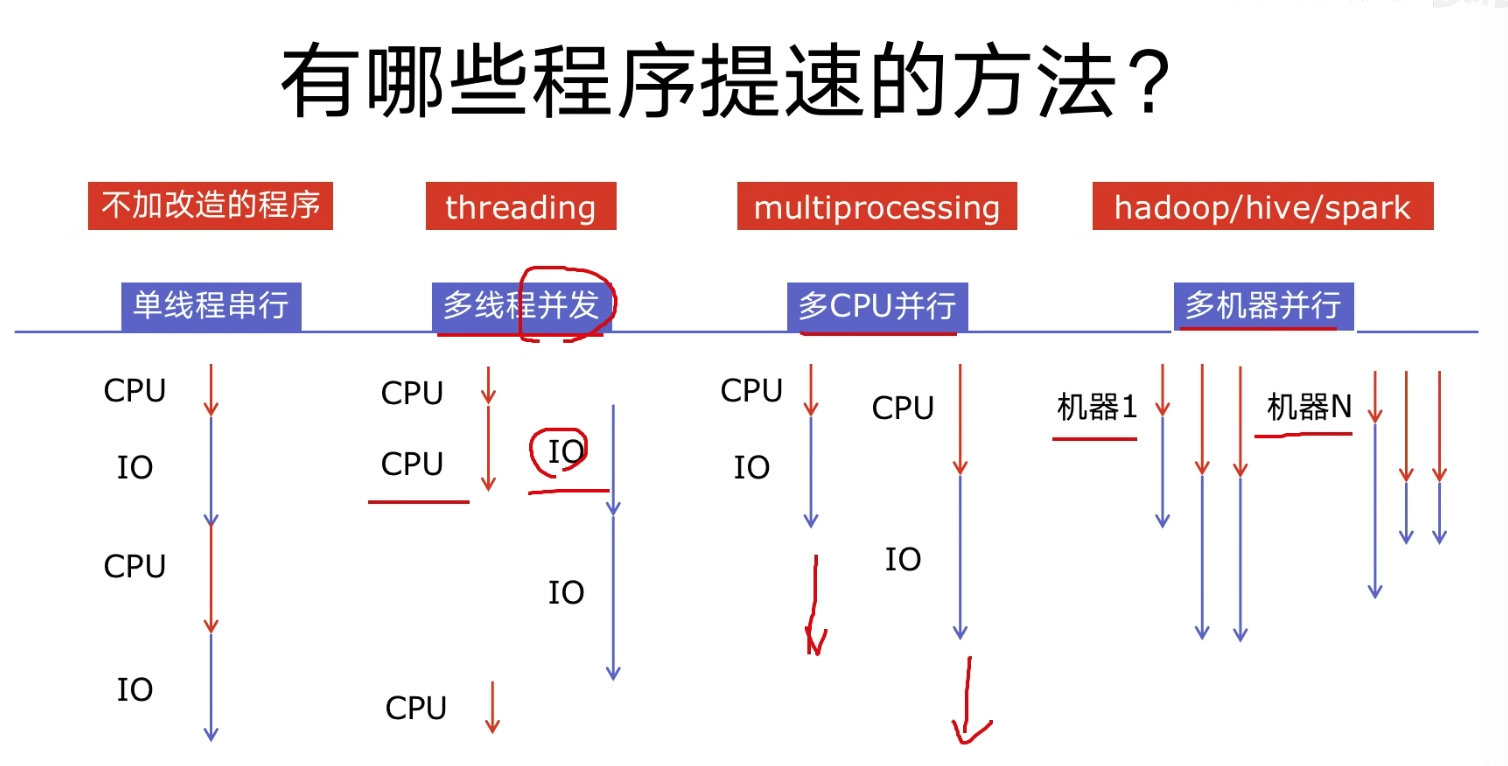
有哪些程序提速方法?
- 单线程串行
- 多线程并发
- 多CPU并行
- 多机器并行
python 对并发的支持
- 多线程 threading
- 多进程 multiprocession
- 异步IO asyncio
- 使用 lock,对资源进行加锁,防止冲突
- 使用 Queue,实现不同线程/进程之间的数据通信
- 线程Pool/进程Pool
- subprocess启动外部进程

如何选择
- 多线程 Thread
- 多进程 Process
- 多协程 Coroutine
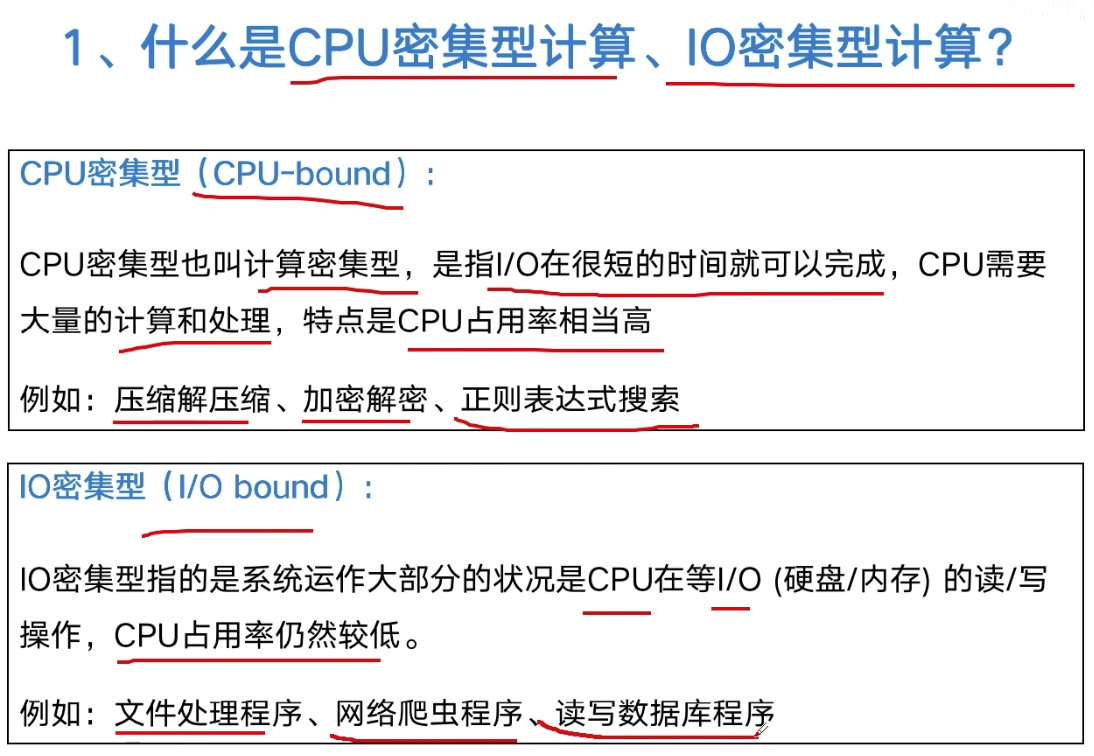
CPU密集型计算
- CPU bound(受限)
- CPU需要很大量的计算,CPU占有率高
- IO 很快
IO 密集型
- IO bound(受限)
- 大部分状况是在 IO(磁盘/内存/网络)的读写操作
- CPU占有率很低
多线程/进程/协程
- 多进程: 比较消耗性能
- 多线程: 在 python中有 GIL(全局解释性锁)限制,只能利用一个CPU,线程间的切换有开销
- 多协程: 技术较新,开销小,性能好,但支持库较少

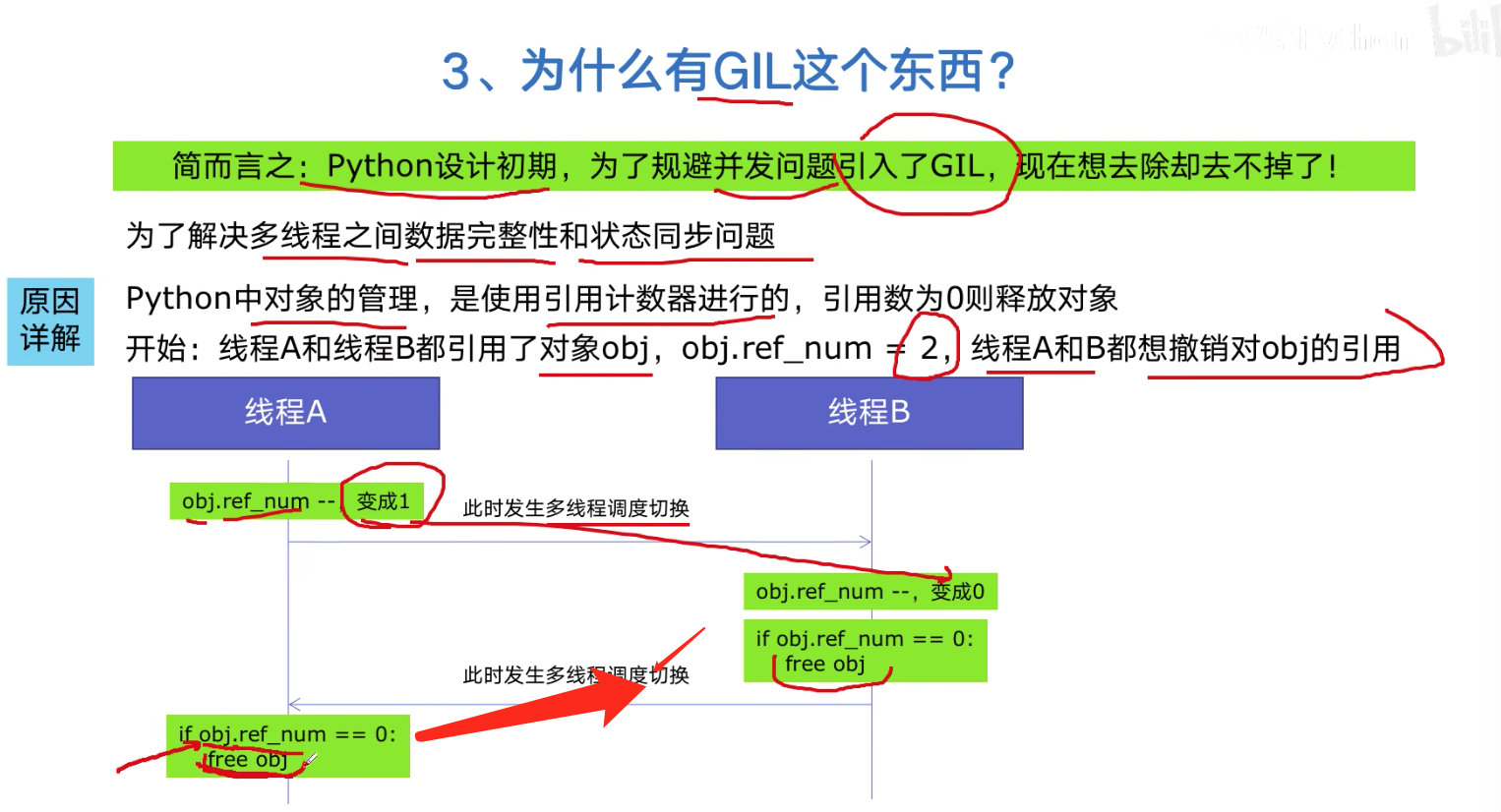
全局解释性锁 GIL
- 任何情况只有一个线程在执行
- GIL同一时间执行一个线程
- 为什么有 GIL: 初期引入,为了规避并发的问题,现在很难去掉
- GIL根源: python的内存管理是用引用计数器机制,防止线程间的切换,不小心释放了其它程序的内存,导致意外情况发生

Python慢的原因
- 解释性语言: 边解释边执行
- 无类型:各种类型判断
- GIL: 无法利用多核CPU,

python创建多线程方法

线程 threading 的使用改进爬虫
import threading
import requests
urls = [
f'https://cnblogs.com/#p{page}'
for page in range(1, 4)
]
def crawl(url):
response = requests.get(url)
print(url, len(response.text))
def single_thread():
for url in urls:
crawl(url)
def multiple_thread():
threads = []
for url in urls:
thread = threading.Thread(
target=crawl,
args=(url,)
)
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
# 运行多线程版本
multiple_thread()
Colipolt代码提示,改进版本
import requests
import time
import threading
urls = [
f'https://www.cnblogs.com/#p{page}'
for page in range(1, 50 + 1)
]
def single_spider(url):
res = requests.get(url)
print(url, len(res.text))
def multi_thread_spider(urls):
threads = []
for url in urls:
t = threading.Thread(target=single_spider, args=(url,))
t.start()
threads.append(t)
for t in threads:
t.join()
if __name__ == '__main__':
# calc duraiton:
start = time.time()
multi_thread_spider(urls)
end = time.time()
print('duration: ', end - start)Queue 实现生产者/消费者爬虫

第1步:改写爬虫为生产者,消费者模式
import threading
import requests
from bs4 import BeautifulSoup
urls = [
f'https://cnblogs.com/#p{page}'
for page in range(1, 4)
]
# 生产者
def crawl(url):
response = requests.get(url)
return response.text
# 消费者
def parse(html):
soup = BeautifulSoup(html, 'html.parser')
# link css selector: .post-item-title
links = soup.select('.post-item-title')
results = []
for link in links:
href = link.get('href')
title = link.get_text()
results.append({
'href': href,
'title': title
})
return results
html = crawl(urls[0])
res = parse(html)
print(res)第2步: 多线程版本的生产者/消费者模式
import threading
import requests
import queue
import time
import random
from bs4 import BeautifulSoup
urls = [
f'https://cnblogs.com/#p{page}'
for page in range(1, 11)
]
# 生产者
def crawl(url):
response = requests.get(url)
return response.text
# 消费者
def parse(html):
soup = BeautifulSoup(html, 'html.parser')
# link css selector: .post-item-title
links = soup.select('.post-item-title')
results = []
for link in links:
href = link.get('href')
title = link.get_text()
results.append({
'href': href,
'title': title
})
return results
def do_crawl(url_queue, html_queue):
while True:
url = url_queue.get()
html = crawl(url)
html_queue.put(html)
print(
threading.current_thread().name,
'url_queue size: ', url_queue.qsize(),
)
time.sleep(random.randint(1, 2))
def do_parse(html_queue, file):
while True:
html = html_queue.get()
results = parse(html)
for result in results:
file.write(str(result) + '\n')
print(
threading.current_thread().name,
'html_queue size: ', html_queue.qsize(),
)
time.sleep(random.randint(1, 2))
# 这里的线程启动没有 join
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in urls:
url_queue.put(url)
file = open('results.txt', 'w')
# create 5 threads for crawl
for _ in range(5):
t = threading.Thread(target=do_crawl, args=(
url_queue, html_queue), name='crawl')
t.start()
# create 3 threads for parse
for _ in range(3):
t = threading.Thread(target=do_parse, args=(
html_queue, file), name='parse')
t.start()
print('main thread end')线程安全问题以及 Lock
- 什么线程安全问题?
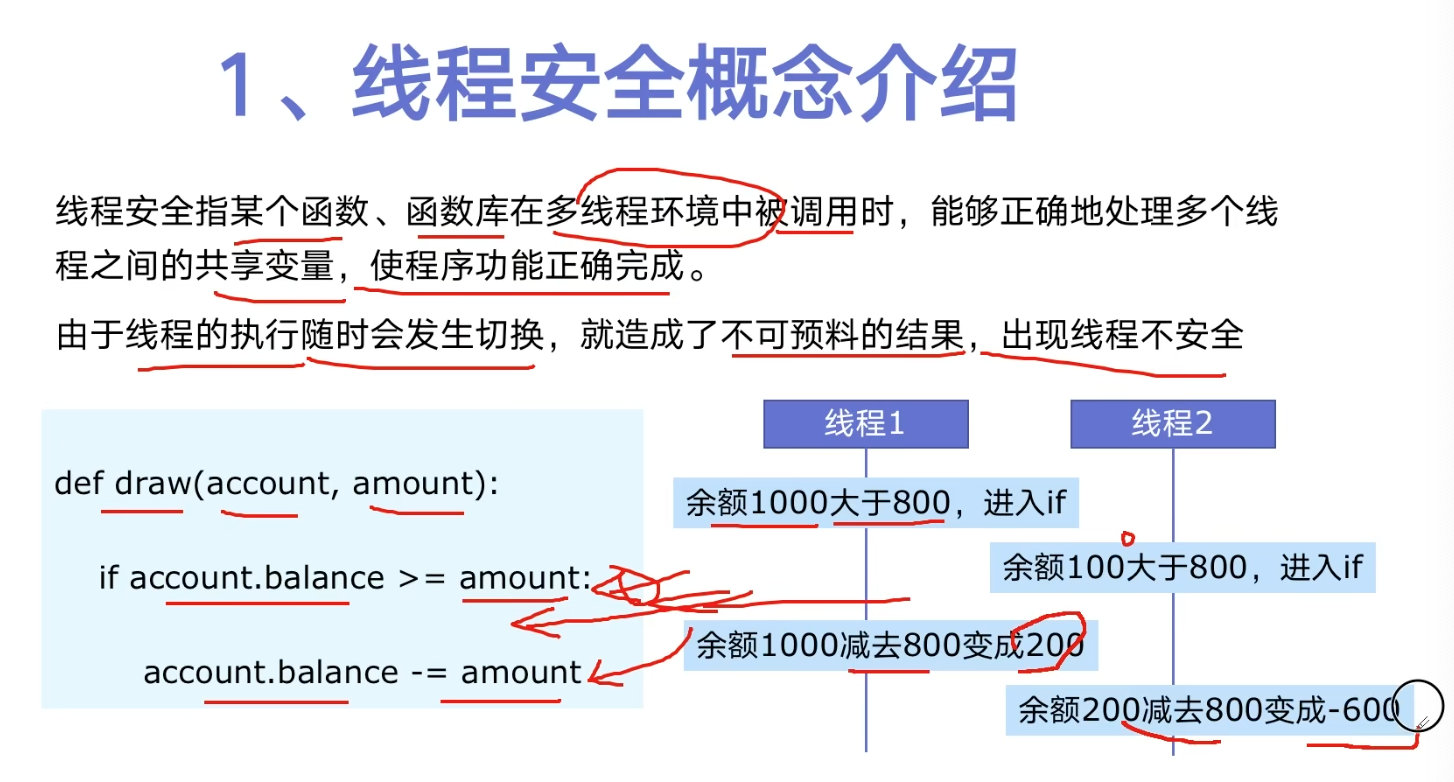

取钱问题代码演示
- 无线程锁
- 有
lock情况,处理线程安全问题
import threading
import time
# 账户
class Account:
def __init__(self, balance):
self.balance = balance
# 转账
def withdraw(account, amount):
if account.balance >= amount:
time.sleep(0.01)
account.balance -= amount
print(threading.current_thread().name, "取钱成功,余额为:", account.balance)
else:
print(threading.current_thread().name, "取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
t1 = threading.Thread(target=withdraw, args=(account, 800), name="t1")
t2 = threading.Thread(target=withdraw, args=(account, 800), name="t2")
t1.start()
t2.start()
t1.join()
t2.join()在多线程的情况下,无锁会出现异常。
t2 取钱成功,余额为: 200
t1 取钱成功,余额为: -600
lock = threading.Lock()+ with lock 解决并发问题
import threading
import time
# 用 lock 解决并发问题
lock = threading.Lock()
# 账户
class Account:
def __init__(self, balance):
self.balance = balance
# 转账
def withdraw(account, amount):
# 获取锁
with lock:
if account.balance >= amount:
time.sleep(0.01)
account.balance -= amount
print(threading.current_thread().name, "取钱成功,余额为:", account.balance)
else:
print(threading.current_thread().name, "取钱失败,余额不足")
if __name__ == "__main__":
account = Account(1000)
t1 = threading.Thread(target=withdraw, args=(account, 800), name="t1")
t2 = threading.Thread(target=withdraw, args=(account, 800), name="t2")
t1.start()
t2.start()
t1.join()
t2.join()