Scrapy学习: 一种分布式爬虫的实现
自己结合 mysql 实现的一种简单分布式爬虫
🕐
设计思路
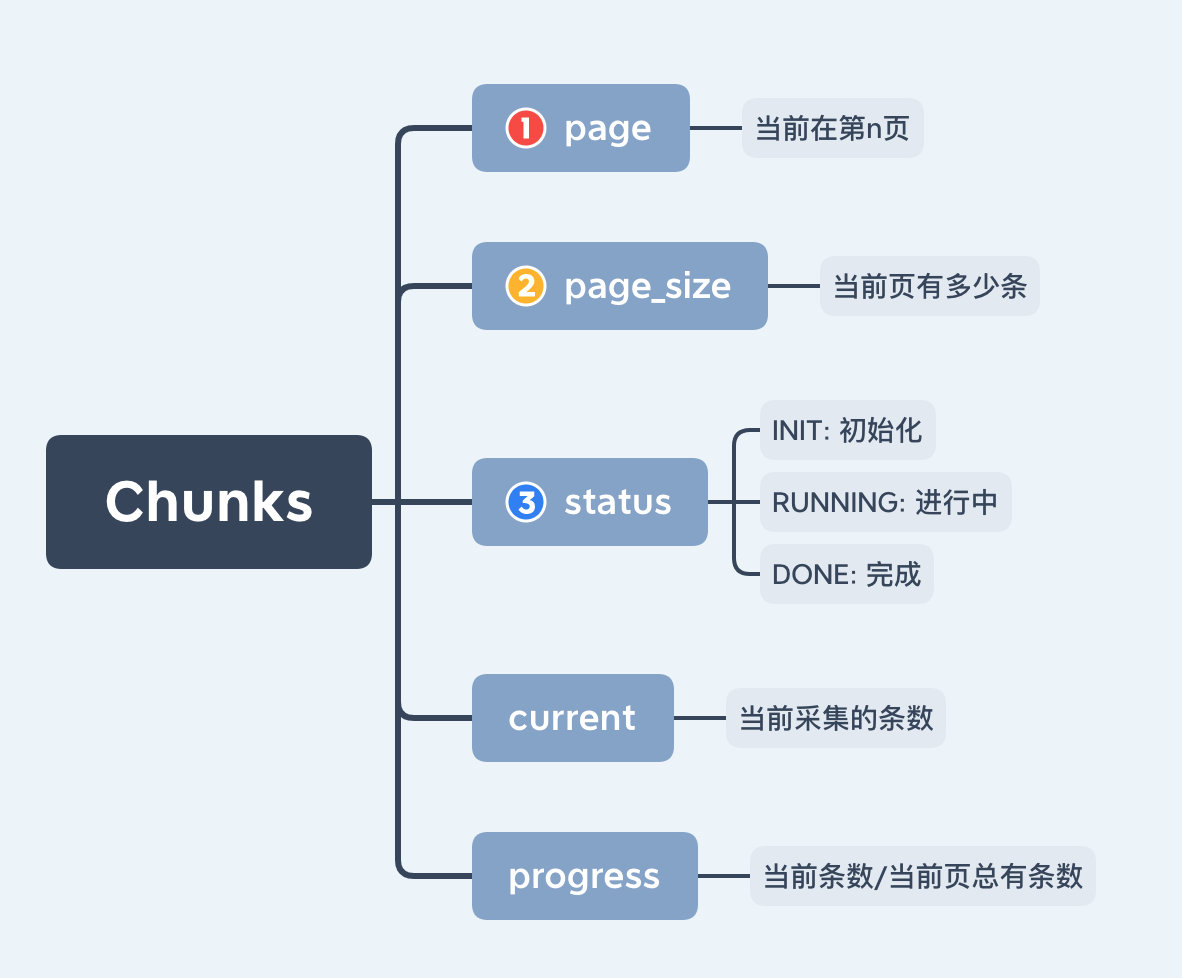
- 将所有要采集的URL分成
chunks,在设定里有CHUNK_SIZE这个setting - 每个
chunk有三种状态:INIT/RUNNING/DONEinit: 初始化的状态running: 每个chunk开始采集的时候,就会是这个状态了done: 当前chunk采集完成
scrapy settings
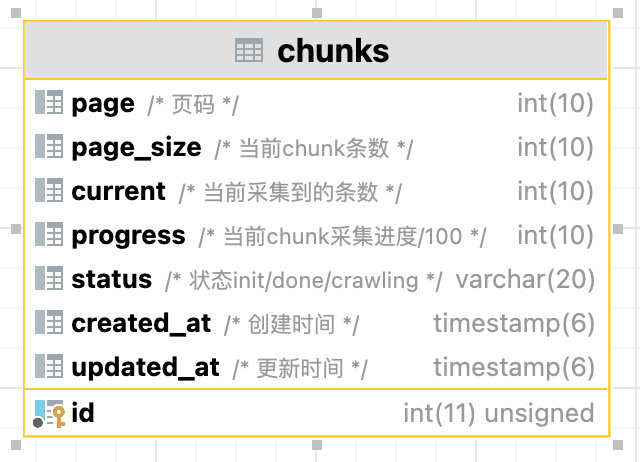
CHUNK_SIZE = 30spider_chunk.py
KninfoDetail是要采集的目标URL表。
import scrapy
import jsw_nx as nx
from spider_knlib.models.kninfo_detail import KninfoDetail
from spider_knlib.settings import CHUNK_SIZE
class ChunkSpider(scrapy.Spider):
name = 'chunk'
handle_httpstatus_list = [400]
start_urls = ['https://www.baidu.com/']
custom_settings = {
'CONCURRENT_REQUESTS': 100,
}
@property
def total(self):
return KninfoDetail.select().count()
def parse(self, response, **kwargs):
total = self.total
pages = total // CHUNK_SIZE + 1
for page in range(1, pages + 1):
page_size = CHUNK_SIZE if page < pages else total % CHUNK_SIZE
yield {
'page': page,
'page_size': page_size,
'current': 0,
'progress': 0,
'status': 'INIT'
}简单实现
- models/chunk
- spider
import datetime
from peewee import *
from ..db import db
class Chunk(Model):
page = IntegerField()
page_size = IntegerField()
current = IntegerField()
progress = IntegerField()
status = CharField()
created_at = DateTimeField(default=datetime.datetime.now())
updated_at = DateTimeField(default=datetime.datetime.now())
@classmethod
def update_status(cls, instance, status):
instance.status = status
instance.save()
class Meta:
database = db
table_name = 'chunks'import scrapy
import jsw_nx as nx
from spider_knlib.models.kninfo_detail import KninfoDetail
from spider_knlib.models.chunk import Chunk
from spider_knlib.loaders import SpiderKnlibItemLoader
from spider_knlib.items import SpiderKnlibItem
from spider_knlib.settings import CHUNK_SIZE
class KninfoDetailChunkSpider(scrapy.Spider):
name = 'kninfo_detail_chunk'
handle_httpstatus_list = [400]
start_urls = ['https://www.baidu.com/']
latest_chunk = None
records = None
custom_settings = {
'CONCURRENT_REQUESTS': 20
}
@property
def is_finished(self):
crawled_count = KninfoDetail.select().where(
KninfoDetail.is_crawled == False).count()
return crawled_count == 0
@staticmethod
def close(spider, reason):
res = super().close(spider, reason)
if reason == 'finished':
Chunk.update_status(spider.latest_chunk, 'DONE')
spider.latest_chunk = None
return res
def init_records(self):
self.latest_chunk = Chunk.select().where(Chunk.status == 'INIT').first()
page = self.latest_chunk.page
self.logger.info(
f'Current chunk is: {self.latest_chunk.page}/{self.latest_chunk.status}')
self.records = KninfoDetail.select().paginate(page, CHUNK_SIZE)
Chunk.update_status(self.latest_chunk, 'RUNNING')
def start_requests(self):
self.init_records()
records = self.records
self.logger.info(
f'Current records/start_records count is: {len(records)}')
if self.is_finished:
nx.notify(
body=f'All records is finished - from spider: {self.name}')
self.logger.info('All records are crawled')
for record in records:
url = record.ncbi_sview_url
self.logger.info(f'Current url is: {url}')
yield scrapy.Request(url, callback=self.parse_ncbi_sview, meta={'record': record})
def parse(self, response, **kwargs):
record = response.meta['record']
item_l = SpiderKnlibItemLoader(
item=SpiderKnlibItem(), response=response)
yield item_l.load_item()继续改进的地方
- 异常情况下,某台机器上的爬虫停止,下次再启动的时候,会有部分处于
RUNNING状态?- 可以使用的解决方案是,添加一个“巡航”程序,定时将一些
RUNNING状态,但时间(updated_at)距当前时间很久的,状态置为INIT
- 可以使用的解决方案是,添加一个“巡航”程序,定时将一些
- 需要与
pm2等进程守护程序配合使用 - 配合
docker,方便部署- 单台机器,多个
docker?
- 单台机器,多个
测试爬虫运行
该爬虫单条数据的开销比较大,所以,未优化前爬取速度比较慢。
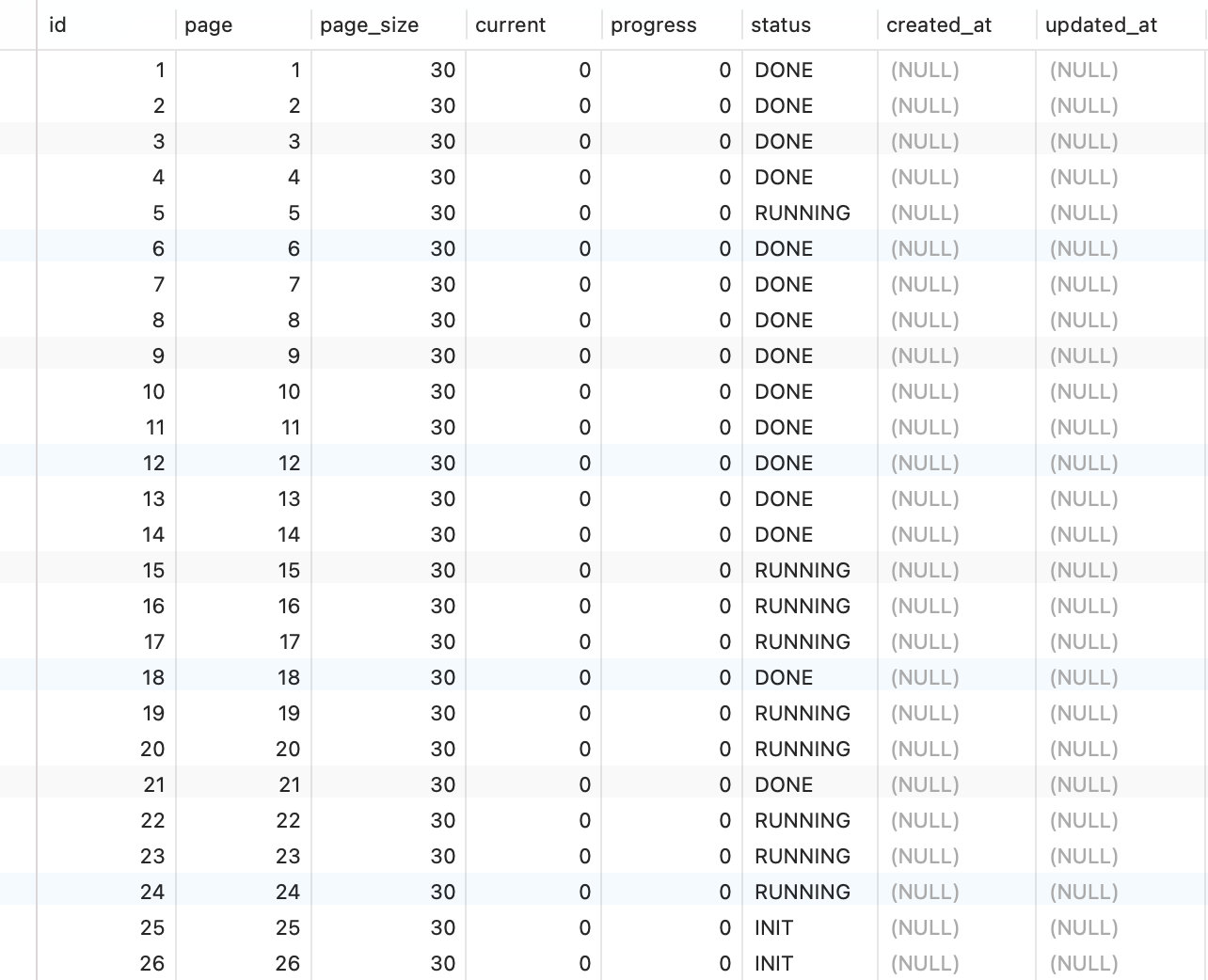
#1台/1进程/10协程/每分钟/30 -> 58 (28)
#2台/1进程/10协程/每分钟/73 -> 114 (41)
#2台/8进程Pool/10协程/每分钟/215 -> 394 (179)